Laporan Proyek Sains Data 1#
Analisis dan Prediksi Harga Bitcoin (BTC) Menggunakan Data Historis sebagai Dasar Pengambilan Keputusan Investasi#
PENDAHULUAN#
Latar Belakang#
Bitcoin (BTC; simbol: ₿) adalah cryptocurrency pertama yang terdesentralisasi, menggunakan teknologi blockchain untuk mencatat transaksi secara aman dan terbuka sejak diperkenalkan pada 2008 oleh Satoshi Nakamoto. Sebagai pelopor aset digital, Bitcoin menggunakan mekanisme proof of work (PoW) untuk mengamankan jaringan, meski sering dikritik karena konsumsi listriknya yang tinggi. Selain sebagai mata uang, Bitcoin lebih sering dianggap sebagai instrumen investasi, dengan El Salvador menjadi negara pertama yang mengadopsinya sebagai alat pembayaran sah pada 2021. Namun, sifatnya yang pseudonim dan volatilitasnya yang tinggi menarik perhatian regulator dan memicu larangan di beberapa negara, meskipun popularitasnya terus meningkat.
Nilai Bitcoin cenderung sangat fluktuatif, dengan perubahan yang signifikan dalam waktu singkat. Beragam faktor seperti sentimen pasar global, tingkat penerimaan teknologi, kebijakan pemerintah, dan kondisi ekonomi dunia menjadi pemicu utama volatilitas tersebut. Ketidakstabilan ini sering kali menyulitkan investor dalam mengelola portofolio mereka secara optimal.
Sebagai solusi, teknologi kecerdasan buatan seperti machine learning dapat dimanfaatkan untuk mengatasi tantangan ini. Dengan memanfaatkan data historis, metode ini mampu menghasilkan prediksi harga yang lebih akurat, mengurangi ketidakpastian, dan mendukung pengambilan keputusan investasi yang lebih bijaksana dan strategis. Bitcoin terus menjadi inovasi yang merevolusi cara pandang dunia terhadap keuangan digital, menciptakan peluang besar sekaligus tantangan baru dalam ekosistemnya.
Tujuan#
Proyek ini bertujuan untuk mengembangkan model prediksi harga cryptocurrency Bitcoin (BTC) berdasarkan data historis. Melalui analisis ini, diharapkan dapat membantu investor dalam membuat keputusan investasi yang lebih tepat serta memberikan wawasan mengenai potensi pergerakan harga Bitcoin untuk memaksimalkan keuntungan dan mengelola risiko secara lebih efektif.
Rumusan Masalah#
- Bagaimana mengembangkan model prediksi harga Bitcoin (BTC) yang dapat diandalkan dengan menggunakan data historis, dan bagaimana hasil prediksi tersebut dapat membantu dalam pengambilan keputusan investasi yang lebih strategis di pasar cryptocurrency?
METODOLOGI#
Data Understanding#
a. Sumber Data#
Data yang digunakan pada proyek ini diambil dari platform Yahoo Finance, yang beralamat di https://finance.yahoo.com/quote/BTC-USD/. Platform ini menyediakan informasi harga Bitcoin (BTC) yang mencakup data historis harga Bitcoin terhadap dolar AS (USD) dari berbagai periode waktu. Informasi ini termasuk harga penutupan, perubahan harga harian, dan berbagai fitur analisis pasar. Dalam proyek ini, digunakan data harga Bitcoin yang tersedia dalam format CSV, mencakup periode dari tanggal 2020 Januari 01 hingga 2024 Desember 06.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_percentage_error
import seaborn as sns
import matplotlib.pyplot as plt
# Membaca data
#Mengambil dan menampilkan data
df = pd.read_csv('https://raw.githubusercontent.com/chacalala/psd/refs/heads/main/bitcoin.csv')
pd.options.display.float_format = '{:.0f}'.format
print(df.head())
Date Open High Low Close Adj Close Volume
0 2020-01-01 7195 7254 7175 7200 7200 18565664997
1 2020-01-02 7203 7212 6935 6986 6986 20802083465
2 2020-01-03 6984 7414 6915 7345 7345 28111481032
3 2020-01-04 7345 7427 7310 7411 7411 18444271275
4 2020-01-05 7410 7544 7400 7411 7411 19725074095
Di sini, perubahan dilakukan agar kolom Date bisa diproses dengan benar sebagai tanggal. Dengan mengubahnya ke format datetime, kita bisa lebih mudah melakukan perbandingan atau analisis berdasarkan waktu. Kemudian, menjadikan Date sebagai indeks membuat data lebih mudah dicari berdasarkan tanggal, dan menyortirnya memastikan data tersusun dengan urutan waktu yang benar.
# mengubah kolom 'Date' dalam format datetime
df['Date'] = pd.to_datetime(df['Date'])
# Mengatur kolom 'Date' sebagai indeks
df.set_index('Date', inplace=True)
# Mensortir data berdasarkan kolom Date dari terkecil ke terbesar
df = df.sort_values(by='Date')
df
| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2020-01-01 | 7195 | 7254 | 7175 | 7200 | 7200 | 18565664997 |
| 2020-01-02 | 7203 | 7212 | 6935 | 6986 | 6986 | 20802083465 |
| 2020-01-03 | 6984 | 7414 | 6915 | 7345 | 7345 | 28111481032 |
| 2020-01-04 | 7345 | 7427 | 7310 | 7411 | 7411 | 18444271275 |
| 2020-01-05 | 7410 | 7544 | 7400 | 7411 | 7411 | 19725074095 |
| ... | ... | ... | ... | ... | ... | ... |
| 2024-12-02 | 97276 | 98153 | 94483 | 95865 | 95865 | 72680784305 |
| 2024-12-03 | 95855 | 96297 | 93630 | 96002 | 96002 | 67067810961 |
| 2024-12-04 | 95988 | 99207 | 94660 | 98768 | 98768 | 77199817112 |
| 2024-12-05 | 98742 | 103900 | 91999 | 96594 | 96594 | 149218945580 |
| 2024-12-06 | 97074 | 102040 | 96515 | 99921 | 99921 | 94534772658 |
1802 rows × 6 columns
b. Deskripsi Dataset#
Dataset ini terdiri dari 8 fitur atau kolom, dan 2230 record atau baris. Berikut adalah penjelasan setiap atribut:
- Date: Tanggal data harga aset koin (format YYYY-MM-DD)
- Open: Harga pembukaan aset koin pada tanggal tersebut
- High: Harga tertinggi yang dicapai pada tanggal tersebut
- Low: Harga terendah aset koin pada tanggal tersebut
- Close: Harga penutupan aset koin pada tanggal tersebut
- Adj Close: Harga penutupan yang sudah disesuaikan dengan pembagian aset koin, dividen, dan corporate actions lainnya
- Volume: Jumlah aset koin yang diperdagangkan pada tanggal tersebut
Selanjutnya, memeriksa informasi tentang dataset untuk melihat jumlah baris dan kolom, serta tipe data dari masing-masing kolom. Ini membantu kita memastikan bahwa semua data sudah lengkap dan tidak ada yang hilang. Selain itu, kita juga ingin mengetahui ukuran data untuk melihat berapa banyak baris dan kolom yang ada. Dari hasil ini, kita bisa tahu bahwa dataset memiliki 1802 baris dan 6 kolom, dengan data yang lengkap dan tipe data yang sesuai.
df.info()
print('Ukuran data ', df.shape)
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 1802 entries, 2020-01-01 to 2024-12-06
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Open 1802 non-null float64
1 High 1802 non-null float64
2 Low 1802 non-null float64
3 Close 1802 non-null float64
4 Adj Close 1802 non-null float64
5 Volume 1802 non-null int64
dtypes: float64(5), int64(1)
memory usage: 98.5 KB
Ukuran data (1802, 6)
c. Eksplorasi Data#
Setelah itu, melihat apakah didalam data set tersebut ada missing value.
df.isnull().sum()
Open 0
High 0
Low 0
Close 0
Adj Close 0
Volume 0
dtype: int64
Setelah dilakukan pengecekan dan ternyata tidak ada missing value maka langkah selanjutnya yaitu membuat visualisasi tren data untuk setiap kolom dalam dataset. Dengan menggunakan `matplotlib` dan `seaborn`, kita akan menggambar grafik garis untuk setiap kolom, dengan tanggal sebagai sumbu X dan nilai kolom sebagai sumbu Y. Setiap grafik akan menampilkan tren perubahan nilai kolom tersebut seiring waktu, lengkap dengan label sumbu dan judul yang menjelaskan kolom yang sedang dianalisis. Grafik ini juga akan dilengkapi dengan grid dan rotasi sumbu X agar lebih mudah dibaca.
import matplotlib.pyplot as plt
import seaborn as sns
for col in df:
plt.figure(figsize=(7, 3))
sns.lineplot(data=df, x='Date', y=col)
plt.title(f'Trend of {col}')
plt.xlabel('Date')
plt.ylabel(col)
plt.grid(True)
plt.xticks(rotation=45)
plt.show()
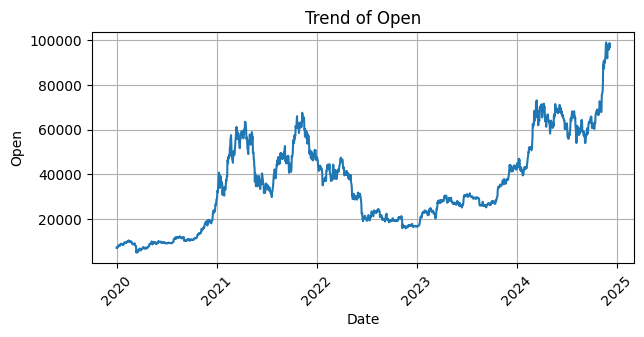
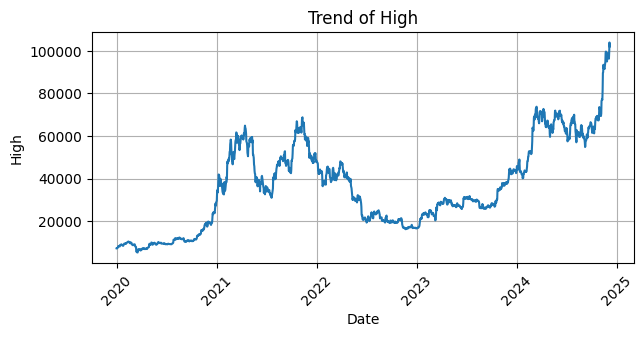
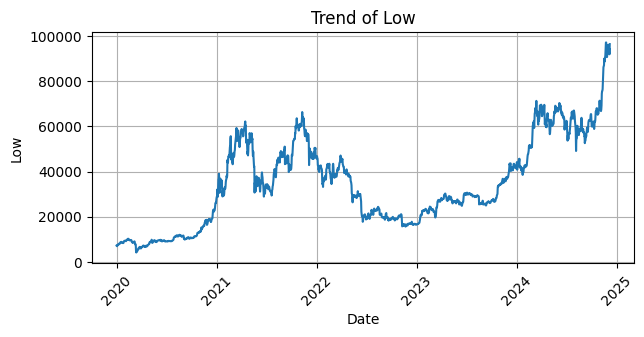
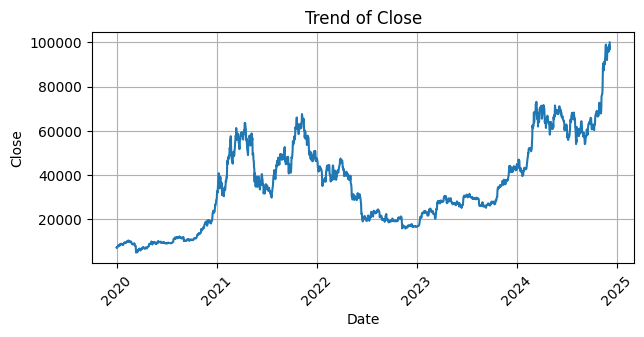
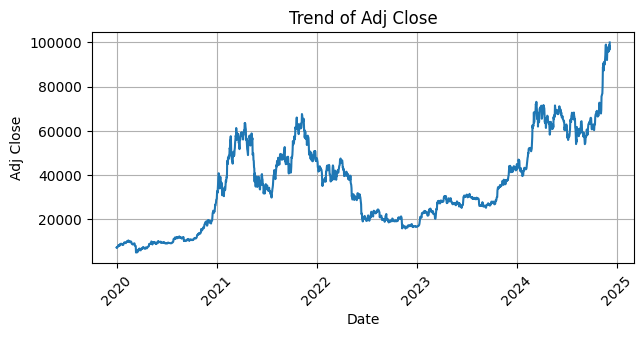
Selanjutnya melakukan pengecekan struktur dataset
df.info()
print('Ukuran data ', df.shape)
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 1802 entries, 2020-01-01 to 2024-12-06
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Open 1802 non-null float64
1 High 1802 non-null float64
2 Low 1802 non-null float64
3 Close 1802 non-null float64
4 Adj Close 1802 non-null float64
5 Volume 1802 non-null int64
dtypes: float64(5), int64(1)
memory usage: 98.5 KB
Ukuran data (1802, 6)
Setelah itu, di sini kita akan menganalisis hubungan antar fitur dalam dataset. Heatmap ini membantu kita memahami korelasi antara kolom-kolom yang ada, apakah ada hubungan yang kuat, lemah, atau tidak ada korelasi sama sekali. Ini dapat memberikan wawasan penting untuk analisis lebih lanjut atau pembuatan model, seperti memilih fitur yang relevan atau mendeteksi multikolinearitas.
correlation_matrix = df.corr()
plt.figure(figsize=(7, 3))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', linewidths=0.5)
plt.title('Heatmap Korelasi Antar Fitur')
plt.show()
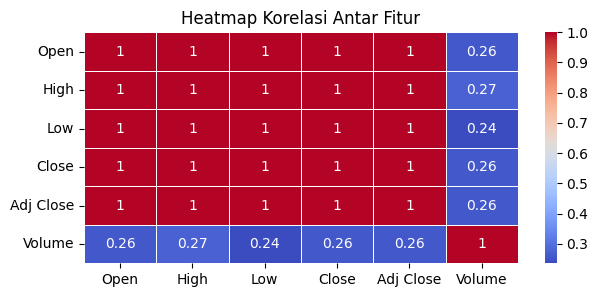
Hasil korelasi pada heatmap ini menunjukkan hubungan antara fitur-fitur dalam data. Nilai korelasi berkisar dari -1 sampai 1, di mana 1 berarti hubungan sangat kuat dan positif, 0 berarti tidak ada hubungan, dan -1 berarti hubungan sangat kuat namun negatif. Pada heatmap ini, terlihat bahwa fitur "Open," "High," "Low," "Close," dan "Adj Close" memiliki korelasi sempurna (1), yang menunjukkan bahwa nilai-nilai ini sangat saling terkait. Namun, fitur "Volume" memiliki korelasi yang lemah (sekitar 0,26-0,27) terhadap fitur-fitur lainnya, yang berarti perubahan pada "Volume" tidak terlalu berhubungan dengan perubahan pada fitur lainnya.
Data Preprocessing#
a. Penghapusan Kolom yang Tidak Relevan dan Verifikasi Dataset#
Menghapus kolom Volume dan Adj Close dari dataset, kolom-kolom tersebut dihilangkan karena mungkin tidak relevan untuk analisis atau pemodelan selanjutnya. Kemudian, kita akan melihat lima baris pertama dari dataset yang telah diperbarui untuk memastikan perubahan yang dilakukan.
df = df.drop(columns=['Volume', 'Adj Close'])
df.head()
| Open | High | Low | Close | |
|---|---|---|---|---|
| Date | ||||
| 2020-01-01 | 7195 | 7254 | 7175 | 7200 |
| 2020-01-02 | 7203 | 7212 | 6935 | 6986 |
| 2020-01-03 | 6984 | 7414 | 6915 | 7345 |
| 2020-01-04 | 7345 | 7427 | 7310 | 7411 |
| 2020-01-05 | 7410 | 7544 | 7400 | 7411 |
b. Rekayasa Fitur#
Dalam penelitian ini, tujuan kita adalah memprediksi harga Close pada hari berikutnya, sehingga kita memerlukan variabel baru sebagai target. Fitur ini berguna untuk mengetahui sejauh mana harga saham bisa turun, yang memungkinkan investor untuk membeli aset pada harga yang lebih rendah dan meningkatkan peluang keuntungan ketika harga saham naik kembali.
df['Close Target'] = df['Close'].shift(-1)
df = df[:-1]
df.head()
| Open | High | Low | Close | Close Target | |
|---|---|---|---|---|---|
| Date | |||||
| 2020-01-01 | 7195 | 7254 | 7175 | 7200 | 6986 |
| 2020-01-02 | 7203 | 7212 | 6935 | 6986 | 7345 |
| 2020-01-03 | 6984 | 7414 | 6915 | 7345 | 7411 |
| 2020-01-04 | 7345 | 7427 | 7310 | 7411 | 7411 |
| 2020-01-05 | 7410 | 7544 | 7400 | 7411 | 7769 |
Tabel ini menunjukkan data harga saham harian yang mencakup harga pembukaan (Open), harga tertinggi (High), harga terendah (Low), dan harga penutupan (Close). Selain itu, terdapat kolom Close Target yang merupakan prediksi harga penutupan untuk hari berikutnya. Misalnya, pada 2020-01-01, harga penutupan adalah 7200.2, sementara prediksi harga penutupan untuk 2020-01-02 adalah 6985.5, yang lebih rendah dari harga penutupan hari itu.
c. Normalisasi Data#
Melakukan normalisasi data pada fitur dan target bertujuan untuk mengubah nilai-nilai dalam dataset ke rentang yang seragam, biasanya antara 0 dan 1. Dalam kode ini, `MinMaxScaler` digunakan untuk menormalisasi fitur (Open, High, Low, Close) dan target (Close Target). Fitur dinormalisasi menggunakan scaler_features.fit_transform() dan target menggunakan scaler_target.fit_transform(). Hasil normalisasi kemudian digabungkan dengan pd.concat() menjadi satu dataframe df_normalized, yang siap digunakan dalam model machine learning. Normalisasi membantu model belajar lebih efektif dengan skala data yang konsisten.
# Inisialisasi scaler untuk fitur (input) dan target (output)
scaler_features = MinMaxScaler()
scaler_target = MinMaxScaler()
# Normalisasi fitur (Open, High, Low,, 'Close' Close Target-4, Close Target-5)
df_features_normalized = pd.DataFrame(scaler_features.fit_transform(df[['Open', 'High', 'Low', 'Close']]),
columns=['Open', 'High', 'Low', 'Close'],
index=df.index)
# Normalisasi target (Close Target)
df_target_normalized = pd.DataFrame(scaler_target.fit_transform(df[['Close Target']]),
columns=['Close Target'],
index=df.index)
# Gabungkan kembali dataframe yang sudah dinormalisasi
df_normalized = pd.concat([df_features_normalized, df_target_normalized], axis=1)
Modelling#
a. Pembagian Data#
Selanjutnya, melakukan pembagian data menjadi data training dan data testing dengan menggunakan train_test_split, di mana 80% data digunakan untuk training dan 20% untuk testing. Proses ini dilakukan dengan opsi shuffle=False agar data tetap terurut berdasarkan urutan aslinya. Setelah pembagian, data training (X_train dan y_train) digunakan untuk melatih model, sedangkan data testing (X_test dan y_test) digunakan untuk menguji kinerja model yang telah dilatih.
# Mengatur fitur (X) dan target (y)
X = df_normalized[['Open', 'High', 'Low', 'Close']]
y = df_normalized['Close Target']
# Membagi data menjadi training dan testing (60% training, 40% testing)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, shuffle=False)
b. Penyusunan Model#
Pada tahap ini, dilakukan percobaan dengan menggunakan tiga model utama, yaitu Regresi Linear, Ridge Linear , dan Gradient Boosting. Selain itu, untuk meningkatkan akurasi dan kinerja model, diterapkan juga teknik ensemble dengan metode bagging
# List model regresi
models = {
"Linear Regression": LinearRegression(),
"Ridge Regression": Ridge(alpha=1.0),
"Gradient Boosting" : GradientBoostingRegressor(random_state=32),
}
# Dictionary untuk menyimpan hasil evaluasi
results = {}
# Iterasi setiap model
for name, model in models.items():
# Latih model
model.fit(X_train, y_train)
# Prediksi pada data uji
y_pred = model.predict(X_test)
# Evaluasi
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
mape = mean_absolute_percentage_error(y_test, y_pred) * 100 # Dalam persen
# Simpan hasil evaluasi
results[name] = {"RMSE": rmse, "MAPE": mape}
# Kembalikan hasil prediksi ke skala asli
y_pred_original = scaler_target.inverse_transform(y_pred.reshape(-1, 1))
y_test_original = scaler_target.inverse_transform(y_test.values.reshape(-1, 1))
# Plot hasil prediksi
plt.figure(figsize=(15, 6))
plt.plot(y_test.index, y_test_original, label="Actual", color="blue")
plt.plot(y_test.index, y_pred_original, label=f"Predicted ({name})", color="red")
# Tambahkan detail plot
plt.title(f'Actual vs Predicted Values ({name})')
plt.xlabel('Date')
plt.ylabel('Harga')
plt.legend()
plt.grid(True)
# Tampilkan plot
plt.show()
# Tampilkan hasil evaluasi
print("HASIL EVALUASI MODEL")
for model, metrics in results.items():
print(f"{model}:\n RMSE: {metrics['RMSE']:.2f}\n MAPE: {metrics['MAPE']:.2f}%\n")
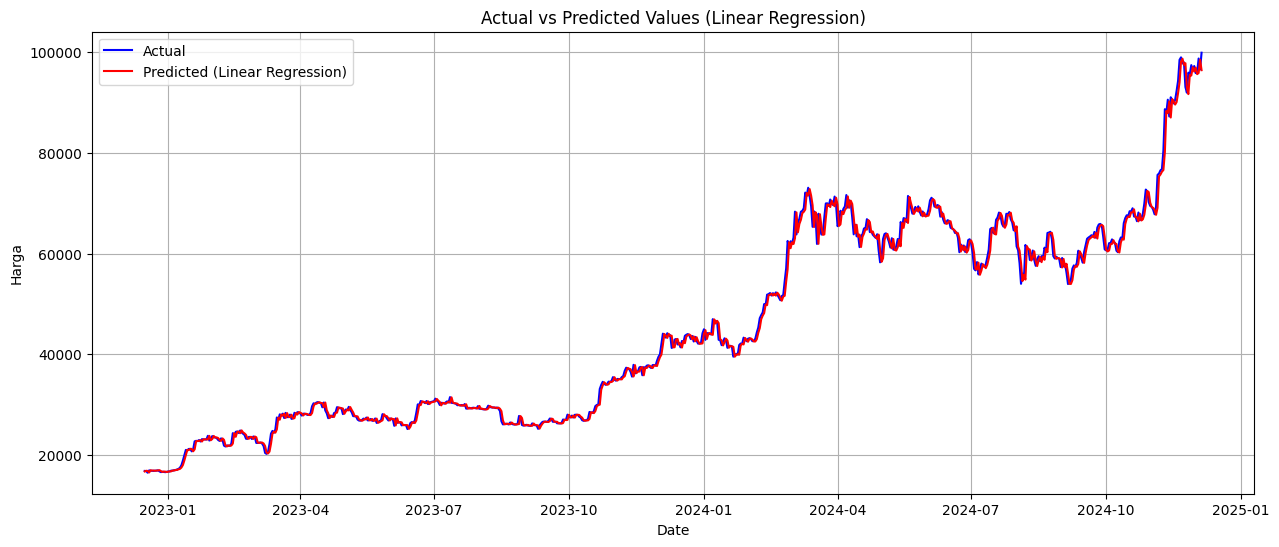
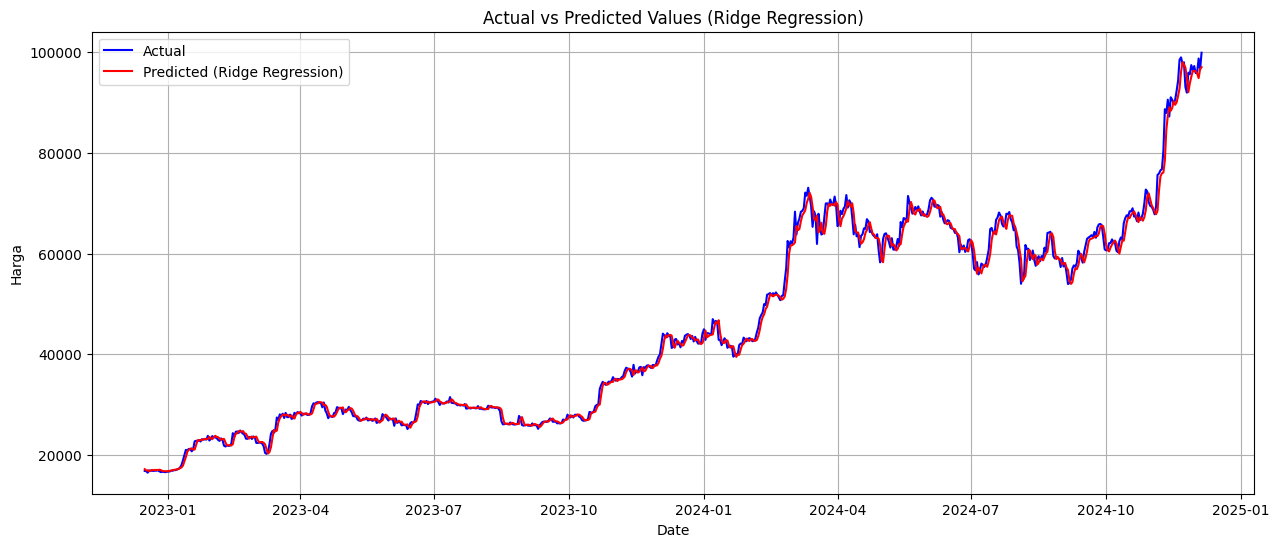
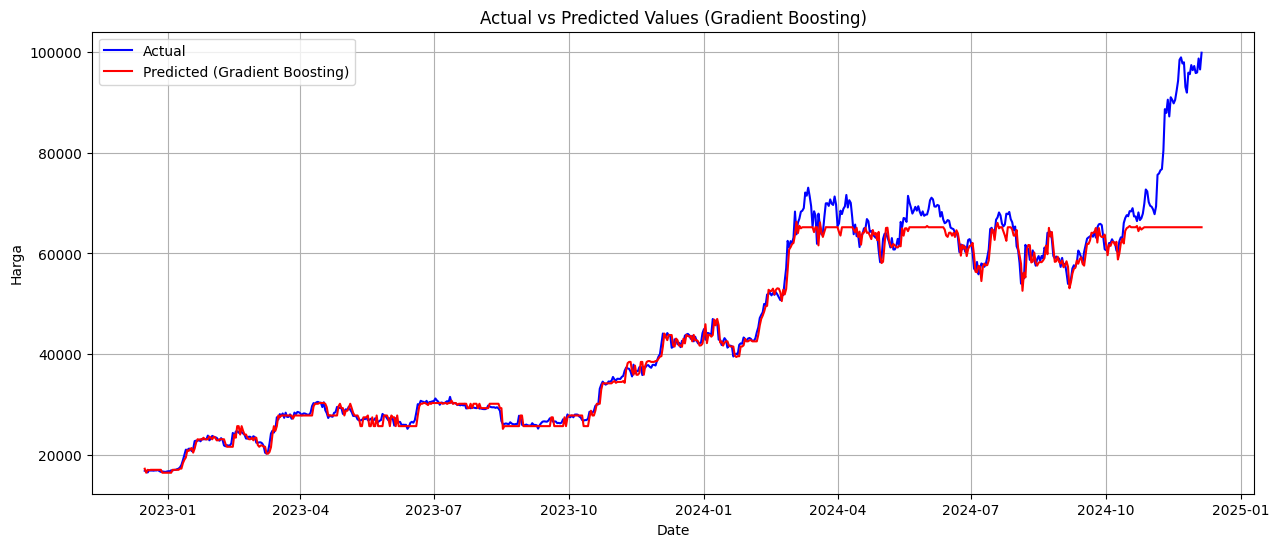
HASIL EVALUASI MODEL
Linear Regression:
RMSE: 0.01
MAPE: 2.01%
Ridge Regression:
RMSE: 0.02
MAPE: 2.21%
Gradient Boosting:
RMSE: 0.06
MAPE: 4.21%
Kesimpulan#
Berdasarkan hasil percobaan dengan beberapa model, metode Linear Regression menunjukkan performa terbaik dengan nilai RMSE sebesar 0.01 dan MAPE sebesar 2.01%.
DEPLOYMENT#
Hasil deployment dapat dilihat melalui tautan berikut: https://huggingface.co/spaces/Alifiacaca/projek1_prediksibtc