Laporan Proyek Sains Data 3#
Prediksi Harga Monero untuk Multi-Step Forecasting Berdasarkan Variabel Multivariat#
PENDAHULUAN#
Latar Belakang#
Monero (XMR) adalah cryptocurrency yang terdesentralisasi dan berfokus pada privasi, pertama kali dirilis pada 2014 sebagai fork dari protokol CryptoNote. Berbeda dengan Bitcoin, Monero dirancang untuk menyediakan anonimitas penuh dalam transaksi, menggunakan teknologi seperti tanda tangan cincin (ring signatures), alamat sekali pakai (stealth addresses), dan mekanisme RingCT (Ring Confidential Transactions) untuk menyembunyikan identitas pengirim, penerima, serta jumlah transaksi. Hal ini menjadikan Monero pilihan populer di kalangan pengguna yang menghargai privasi tinggi, meskipun juga sering mendapat sorotan negatif dari regulator karena potensinya digunakan dalam aktivitas ilegal.
Dalam dunia cryptocurrency, Monero (XMR) menonjol sebagai aset digital yang mengutamakan privasi dan keamanan. Namun, sifat pasar cryptocurrency yang sangat fluktuatif sering kali membuat investor dan pelaku pasar menghadapi tantangan besar dalam mengelola risiko dan memanfaatkan peluang investasi secara optimal. Monero memiliki potensi besar sebagai aset investasi alternatif, terutama bagi individu dan institusi yang menghargai privasi tinggi dalam transaksi keuangan. Akan tetapi, fluktuasi harga yang signifikan menciptakan ketidakpastian, yang pada gilirannya dapat menghambat adopsi lebih luas dan keputusan investasi yang tepat.
Oleh karena itu, pengembangan model prediksi harga Monero menjadi sangat relevan untuk membantu investor memahami dinamika harga Monero secara lebih mendalam, mendukung strategi investasi yang lebih terinformasi dan berbasis data, serta meningkatkan kepercayaan terhadap aset ini dengan menyediakan wawasan yang dapat diandalkan terkait potensi pergerakan harga. Proyek ini dirancang untuk menjawab kebutuhan tersebut, dengan fokus pada pemanfaatan data historis dan teknologi kecerdasan buatan untuk memberikan solusi praktis bagi tantangan yang dihadapi oleh investor di pasar cryptocurrency.
Tujuan#
Proyek ini bertujuan untuk mengembangkan model prediksi harga cryptocurrency Monero (XMR) berdasarkan data historis. Analisis ini diharapkan dapat membantu investor memahami pergerakan harga Monero, memaksimalkan keuntungan, dan mengelola risiko dengan lebih efektif.
Rumusan Masalah#
- Bagaimana mengembangkan model prediksi harga Monero (XMR) yang dapat diandalkan dengan menggunakan data historis, dan bagaimana hasil prediksi tersebut dapat mendukung pengambilan keputusan investasi yang lebih strategis di pasar cryptocurrency?
METODOLOGI#
Data Understanding#
a. Sumber Data#
Data yang digunakan pada proyek ini diambil dari platform Yahoo Finance, yang beralamat di https://finance.yahoo.com/quote/XMR-USD/. Platform ini menyediakan informasi harga Monero (XMR) yang mencakup data historis harga Monero terhadap dolar AS (USD) dari berbagai periode waktu. Informasi ini termasuk harga penutupan, perubahan harga harian, dan berbagai fitur analisis pasar. Dalam proyek ini, digunakan data harga Monero yang tersedia dalam format CSV, mencakup periode dari tanggal 2020 Januari 01 hingga 2024 Desember 06. Bentuk tampilan datanya seperti berikut :
import pandas as pd
# Baca data CSV
df = pd.read_csv('https://raw.githubusercontent.com/chacalala/psd/refs/heads/main/monero.csv')
print(df.head())
Date Open High Low Close Adj Close Volume
0 2020-01-01 0.1929 0.1944 0.1921 0.1927 0.1927 1041134003
1 2020-01-02 0.1927 0.1929 0.1869 0.1880 0.1880 1085351426
2 2020-01-03 0.1879 0.1941 0.1858 0.1935 0.1935 1270017043
3 2020-01-04 0.1935 0.1947 0.1918 0.1944 0.1944 999331594
4 2020-01-05 0.1944 0.1992 0.1939 0.1955 0.1955 1168067557
Di sini, perubahan dilakukan agar kolom Date bisa diproses dengan benar sebagai tanggal. Dengan mengubahnya ke format datetime, kita bisa lebih mudah melakukan perbandingan atau analisis berdasarkan waktu. Kemudian, menjadikan Date sebagai indeks membuat data lebih mudah dicari berdasarkan tanggal, dan menyortirnya memastikan data tersusun dengan urutan waktu yang benar.
# mengubah kolom 'Date' dalam format datetime
df['Date'] = pd.to_datetime(df['Date'])
# Mengatur kolom 'Date' sebagai indeks
df.set_index('Date', inplace=True)
# Mensortir data berdasarkan kolom Date dari terkecil ke terbesar
df = df.sort_values(by='Date')
df
| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2020-01-01 | 0.1929 | 0.1944 | 0.1921 | 0.1927 | 0.1927 | 1041134003 |
| 2020-01-02 | 0.1927 | 0.1929 | 0.1869 | 0.1880 | 0.1880 | 1085351426 |
| 2020-01-03 | 0.1879 | 0.1941 | 0.1858 | 0.1935 | 0.1935 | 1270017043 |
| 2020-01-04 | 0.1935 | 0.1947 | 0.1918 | 0.1944 | 0.1944 | 999331594 |
| 2020-01-05 | 0.1944 | 0.1992 | 0.1939 | 0.1955 | 0.1955 | 1168067557 |
| ... | ... | ... | ... | ... | ... | ... |
| 2024-12-02 | 2.3207 | 2.8497 | 2.2439 | 2.7138 | 2.7138 | 51723383809 |
| 2024-12-03 | 2.7139 | 2.8649 | 2.3610 | 2.5255 | 2.5255 | 43498034453 |
| 2024-12-04 | 2.5256 | 2.6703 | 2.2956 | 2.3544 | 2.3544 | 22033216003 |
| 2024-12-05 | 2.3544 | 2.4850 | 2.1889 | 2.2952 | 2.2952 | 21253973296 |
| 2024-12-06 | 2.2509 | 2.4605 | 2.2395 | 2.4247 | 2.4247 | 13380810341 |
1802 rows × 6 columns
b. Deskripsi Dataset#
Dataset ini terdiri dari 6 fitur atau kolom, dan 1802 record atau baris. Berikut adalah penjelasan setiap atribut:
- Open: Harga pembukaan aset koin pada tanggal tersebut
- High: Harga tertinggi yang dicapai pada tanggal tersebut
- Low: Harga terendah aset koin pada tanggal tersebut
- Close: Harga penutupan aset koin pada tanggal tersebut
- Adj Close: Harga penutupan yang sudah disesuaikan dengan pembagian aset koin, dividen, dan corporate actions lainnya
- Volume: Jumlah aset koin yang diperdagangkan pada tanggal tersebut
Selanjutnya, memeriksa informasi tentang dataset untuk melihat jumlah baris dan kolom, serta tipe data dari masing-masing kolom. Ini membantu kita memastikan bahwa semua data sudah lengkap dan tidak ada yang hilang. Selain itu, kita juga ingin mengetahui ukuran data untuk melihat berapa banyak baris dan kolom yang ada. Dari hasil ini, kita bisa tahu bahwa dataset memiliki 1802 baris dan 6 kolom, dengan data yang lengkap dan tipe data yang sesuai.
df.info()
print('Ukuran data ', df.shape)
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 1802 entries, 2020-01-01 to 2024-12-06
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Open 1802 non-null float64
1 High 1802 non-null float64
2 Low 1802 non-null float64
3 Close 1802 non-null float64
4 Adj Close 1802 non-null float64
5 Volume 1802 non-null int64
dtypes: float64(5), int64(1)
memory usage: 98.5 KB
Ukuran data (1802, 6)
c. Eksplorasi Data#
Setelah itu, melihat apakah didalam data set tersebut ada missing value.
df.isnull().sum()
Open 0
High 0
Low 0
Close 0
Adj Close 0
Volume 0
dtype: int64
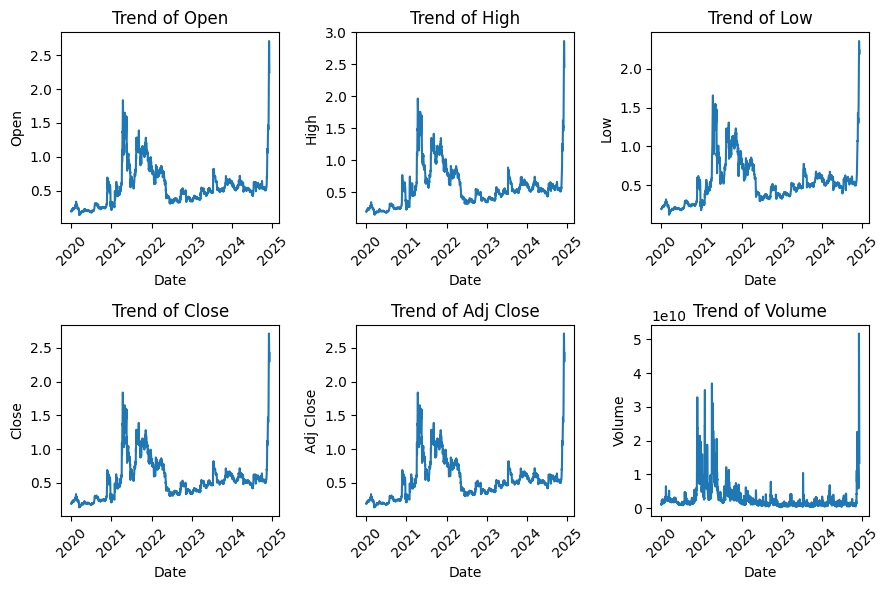
Setelah memastikan bahwa tidak ada missing value dalam dataset, langkah berikutnya adalah membuat visualisasi tren data untuk setiap kolom. Kita akan menggambar grafik garis untuk setiap kolom, dengan tanggal sebagai sumbu X dan nilai kolom sebagai sumbu Y. Setiap grafik akan menampilkan tren perubahan nilai kolom tersebut seiring waktu, lengkap dengan label sumbu dan judul yang menjelaskan kolom yang sedang dianalisis. Grafik ini juga akan dilengkapi dengan grid dan rotasi sumbu X agar lebih mudah dibaca.
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np # Tambahkan ini untuk memperbaiki error
# Membuat subplot otomatis berdasarkan jumlah kolom dalam dataframe
plt.figure(figsize=(9, int(np.ceil(len(df.columns) / 3))*3))
for i, col in enumerate(df.columns):
plt.subplot(int(np.ceil(len(df.columns) / 3)), 3, i + 1)
sns.lineplot(data=df, x='Date', y=col)
plt.title(f'Trend of {col}')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
Selanjutnya membuat histogram dari kolom Open, High, Low, Close, Adj Close, dan Volume bertujuan untuk memvisualisasikan distribusi data pada setiap kolom tersebut. Visualisasi ini membantu kita memahami pola data, seperti apakah data terdistribusi normal, memiliki outlier, atau cenderung miring (skewed). Dengan histogram, kita dapat mengevaluasi karakteristik data sebelum melanjutkan ke tahap analisis atau pemodelan selanjutnya.
df.hist(figsize=(10, 8), column=['Open', 'High', 'Low', 'Close', 'Adj Close', 'Volume'])
array([[<Axes: title={'center': 'Open'}>,
<Axes: title={'center': 'High'}>],
[<Axes: title={'center': 'Low'}>,
<Axes: title={'center': 'Close'}>],
[<Axes: title={'center': 'Adj Close'}>,
<Axes: title={'center': 'Volume'}>]], dtype=object)
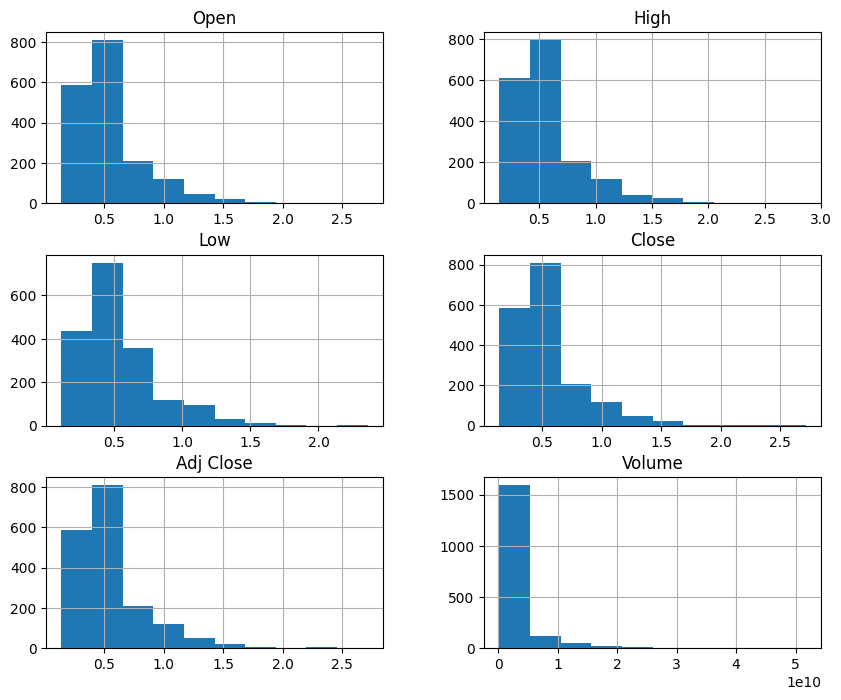
Histogram di atas menunjukkan distribusi nilai dari setiap kolom dalam dataset, termasuk Open, High, Low, Close, Adj Close, dan Volume. Dari visualisasi tersebut, terlihat bahwa sebagian besar data untuk kolom harga (Open, High, Low, Close, dan Adj Close) memiliki distribusi yang cenderung miring ke kanan (positively skewed), dengan sebagian besar nilai terkonsentrasi pada rentang yang lebih rendah. Sementara itu, kolom Volume memiliki distribusi yang sangat tidak merata dengan mayoritas nilai berada di rentang rendah, tetapi terdapat beberapa nilai yang sangat besar (outliers). Hal ini dapat mengindikasikan bahwa sebagian besar volume transaksi relatif kecil, namun ada beberapa transaksi yang jumlahnya sangat tinggi.
Setelah itu, di sini kita akan menganalisis hubungan antar fitur dalam dataset. Heatmap ini membantu kita memahami korelasi antara kolom-kolom yang ada, apakah ada hubungan yang kuat, lemah, atau tidak ada korelasi sama sekali. Ini dapat memberikan wawasan penting untuk analisis lebih lanjut atau pembuatan model, seperti memilih fitur yang relevan atau mendeteksi multikolinearitas.
correlation_matrix = df.corr()
plt.figure(figsize=(7, 3))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', linewidths=0.5)
plt.title('Heatmap Korelasi Antar Fitur')
plt.show()
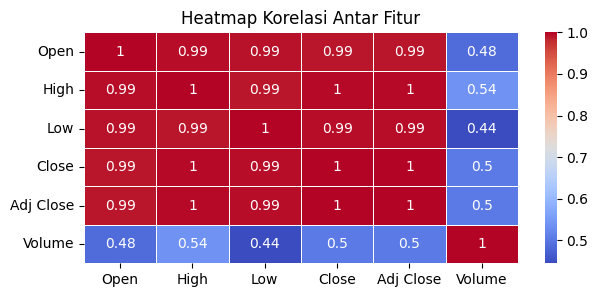
Hasil korelasi pada heatmap ini menunjukkan hubungan antara fitur-fitur dalam data. Nilai korelasi berkisar dari -1 hingga 1, di mana 1 menunjukkan hubungan yang sangat kuat dan positif, 0 menunjukkan tidak ada hubungan, dan -1 menunjukkan hubungan yang sangat kuat namun negatif. Pada heatmap ini, terlihat bahwa fitur Open, High, Low, Close, dan Adj Close memiliki korelasi yang hampir sempurna (mendekati 1), yang menandakan bahwa nilai-nilai dari fitur-fitur ini sangat saling berkaitan dan cenderung bergerak searah. Sementara itu, fitur Volume memiliki korelasi yang lebih lemah dengan fitur lainnya (berkisar antara 0.44 hingga 0.54), menunjukkan bahwa perubahan nilai pada fitur Volume tidak terlalu berhubungan dengan perubahan pada fitur harga lainnya. Interpretasi ini penting dalam analisis data untuk memahami hubungan antar fitur.
Data Preprocessing#
a. Penghapusan Kolom yang Tidak Relevan dan Verifikasi Dataset#
Menghapus kolom Volume dan Adj Close dari dataset, kolom-kolom tersebut dihilangkan karena mungkin tidak relevan untuk analisis atau pemodelan selanjutnya. Kemudian, kita akan melihat lima baris pertama dari dataset yang telah diperbarui untuk memastikan perubahan yang dilakukan.
# Menghapus kolom yang tidak digunakan
df = df.drop(columns=['Volume', 'Adj Close'])
df.head()
| Open | High | Low | Close | |
|---|---|---|---|---|
| Date | ||||
| 2020-01-01 | 0.1929 | 0.1944 | 0.1921 | 0.1927 |
| 2020-01-02 | 0.1927 | 0.1929 | 0.1869 | 0.1880 |
| 2020-01-03 | 0.1879 | 0.1941 | 0.1858 | 0.1935 |
| 2020-01-04 | 0.1935 | 0.1947 | 0.1918 | 0.1944 |
| 2020-01-05 | 0.1944 | 0.1992 | 0.1939 | 0.1955 |
b. Rekayasa Fitur#
Dalam penelitian ini, tujuan kita adalah memprediksi harga Close pada hari berikutnya, sehingga kita memerlukan variabel baru sebagai target. Fitur ini berguna untuk mengetahui sejauh mana harga saham bisa turun, yang memungkinkan investor untuk membeli aset pada harga yang lebih rendah dan meningkatkan peluang keuntungan ketika harga saham naik kembali.
df['Close Target'] = df['Close'].shift(-1)
df = df[:-1]
df.head()
| Open | High | Low | Close | Close Target | |
|---|---|---|---|---|---|
| Date | |||||
| 2020-01-01 | 0.1929 | 0.1944 | 0.1921 | 0.1927 | 0.1880 |
| 2020-01-02 | 0.1927 | 0.1929 | 0.1869 | 0.1880 | 0.1935 |
| 2020-01-03 | 0.1879 | 0.1941 | 0.1858 | 0.1935 | 0.1944 |
| 2020-01-04 | 0.1935 | 0.1947 | 0.1918 | 0.1944 | 0.1955 |
| 2020-01-05 | 0.1944 | 0.1992 | 0.1939 | 0.1955 | 0.2215 |
Tabel ini menunjukkan data harga saham harian yang mencakup harga pembukaan (Open), harga tertinggi (High), harga terendah (Low), dan harga penutupan (Close). Selain itu, terdapat kolom Close Target yang merupakan nilai harga penutupan untuk hari berikutnya. Misalnya, pada 2020-01-01, harga penutupan adalah 0.1927, sementara harga penutupan untuk 2020-01-02 adalah 0.1880, yang lebih rendah dibandingkan harga penutupan pada 2020-01-01. Hal ini memberikan gambaran tren perubahan harga saham dari hari ke hari, serta menyediakan data untuk analisis atau prediksi lebih lanjut..
Pada langkah ini, parameter FORECAST_STEPS digunakan untuk menentukan jumlah langkah ke depan yang ingin diprediksi dalam multi-step forecasting. Nilainya diatur menjadi 5, yang berarti model akan memprediksi nilai target untuk 5 periode atau hari ke depan. Parameter ini dapat disesuaikan sesuai kebutuhan analisis atau tujuan prediksi. Dalam pendekatan Iterative Multi-Step Forecasting, setiap prediksi bergantung pada hasil prediksi sebelumnya, sehingga model akan memprediksi langkah pertama, kemudian menggunakan hasil tersebut sebagai input untuk prediksi langkah kedua, dan seterusnya hingga mencapai jumlah langkah yang ditentukan oleh FORECAST_STEPS. Pendekatan ini memungkinkan prediksi untuk dilakukan beberapa periode ke depan secara bertahap.
# Parameter untuk Multi-Step Forecasting
FORECAST_STEPS = 5 # Jumlah langkah ke depan yang ingin diprediksi
Pada langkah ini, dilakukan proses untuk membuat target prediksi harga berdasarkan parameter FORECAST_STEPS. Target dibuat dengan menggeser nilai harga penutupan ke atas sebanyak 1 hingga FORECAST_STEPS, sehingga menghasilkan kolom prediksi untuk 1 hari, 2 hari, hingga langkah ke depan yang ditentukan. Setelah kolom target selesai dibuat, baris-baris terakhir yang memiliki nilai NaN pada kolom target dihapus untuk menghindari data kosong yang dapat memengaruhi pelatihan model atau analisis.
# Membuat target untuk n langkah ke depan
for i in range(1, FORECAST_STEPS + 1):
df[f'Close Target+{i}'] = df['Close'].shift(-i)
# Menghapus baris yang memiliki nilai NaN pada target
df = df[:-FORECAST_STEPS]
c. Normalisasi Data#
Melakukan normalisasi data pada fitur dan target bertujuan untuk mengubah nilai-nilai dalam dataset ke rentang yang seragam, biasanya antara 0 dan 1. Dalam kode ini, MinMaxScaler digunakan untuk menormalisasi fitur (Open, High, Low, Close) dan target (Close Target). Fitur dinormalisasi menggunakan scaler_features.fit_transform() dan target menggunakan scaler_target.fit_transform(). Hasil normalisasi kemudian digabungkan dengan pd.concat() menjadi satu dataframe df_normalized, yang siap digunakan dalam model machine learning. Normalisasi membantu model belajar lebih efektif dengan skala data yang konsisten.
# Import library yang dibutuhkan
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
# Inisialisasi scaler untuk fitur dan target
scaler_features = MinMaxScaler()
scaler_target = MinMaxScaler()
# Normalisasi fitur
features = ['Open', 'High', 'Low', 'Close']
df_features_normalized = pd.DataFrame(
scaler_features.fit_transform(df[features]),
columns=features,
index=df.index
)
# Normalisasi target
target_columns = [f'Close Target+{i}' for i in range(1, FORECAST_STEPS + 1)]
df_target_normalized = pd.DataFrame(
scaler_target.fit_transform(df[target_columns]),
columns=target_columns,
index=df.index
)
# Menggabungkan kembali dataframe yang sudah dinormalisasi
df_normalized = pd.concat([df_features_normalized, df_target_normalized], axis=1)
Modelling#
a. Pembagian Data#
Selanjutnya, melakukan pembagian data menjadi data training dan data testing dengan menggunakan train_test_split, di mana 80% data digunakan untuk training dan 20% untuk testing. Proses ini dilakukan dengan opsi shuffle=False agar data tetap terurut berdasarkan urutan aslinya. Setelah pembagian, data training (X_train dan y_train) digunakan untuk melatih model, sedangkan data testing (X_test dan y_test) digunakan untuk menguji kinerja model yang telah dilatih.
from sklearn.model_selection import train_test_split # Tambahkan ini
# Mengatur fitur (X) dan target (y)
X = df_normalized[features]
y = df_normalized[target_columns]
# Membagi data menjadi training dan testing
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, shuffle=False)
b. Penyusunan Model#
Pada tahap ini, dilakukan percobaan dengan menggunakan tiga model utama, yaitu Regresi Linear, Ridge Linear , dan Decision Tree. Selain itu, untuk meningkatkan akurasi dan kinerja model, diterapkan juga teknik ensemble dengan metode bagging
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
import numpy as np
import matplotlib.pyplot as plt
# List model regresi
models = {
"Linear Regression": LinearRegression(),
"Decision Tree": DecisionTreeRegressor(random_state=32),
"Ridge Regression": Ridge(alpha=1.0)
}
# Dictionary untuk menyimpan hasil evaluasi
results = {}
# Iterasi setiap model
for name, model in models.items():
# Latih model
model.fit(X_train, y_train)
# Prediksi pada data uji
y_pred = model.predict(X_test)
# Evaluasi untuk setiap target hari ke depan
mse_list = []
mape_list = []
for i in range(FORECAST_STEPS):
mse = mean_squared_error(y_test.iloc[:, i], y_pred[:, i])
mape = mean_absolute_percentage_error(y_test.iloc[:, i], y_pred[:, i]) * 100
mse_list.append(mse)
mape_list.append(mape)
# Simpan hasil evaluasi rata-rata
results[name] = {
"Average RMSE": np.sqrt(np.mean(mse_list)),
"Average MAPE": np.mean(mape_list)
}
# Kembalikan hasil prediksi ke skala asli
y_pred_original = scaler_target.inverse_transform(y_pred)
y_test_original = scaler_target.inverse_transform(y_test)
# Plot hasil prediksi untuk setiap hari
plt.figure(figsize=(15, 6))
for i in range(FORECAST_STEPS):
plt.plot(
y_test.index, y_test_original[:, i], label=f"Actual Target+{i+1}", linestyle="dashed"
)
plt.plot(
y_test.index, y_pred_original[:, i], label=f"Predicted Target+{i+1}", alpha=0.7
)
# Tambahkan detail plot
plt.title(f'Actual vs Predicted Values ({name})')
plt.xlabel('Tanggal')
plt.ylabel('Kurs')
plt.legend()
plt.grid(True)
# Tampilkan plot
plt.show()
# Tampilkan hasil evaluasi
print("HASIL EVALUASI MODEL")
for model, metrics in results.items():
print(f"{model}:")
print(f" Average RMSE: {metrics['Average RMSE']:.2f}")
print(f" Average MAPE: {metrics['Average MAPE']:.2f}%")
# Cari model dengan Average MAPE terbaik (nilai terkecil)
best_model_name = min(results, key=lambda x: results[x]["Average MAPE"])
best_model = models[best_model_name]
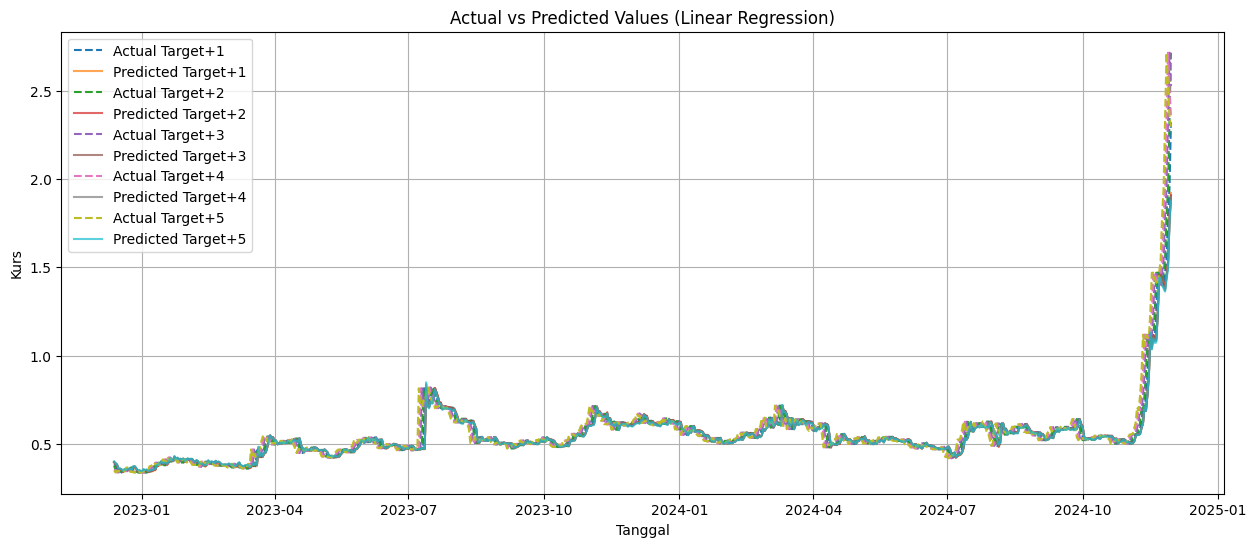
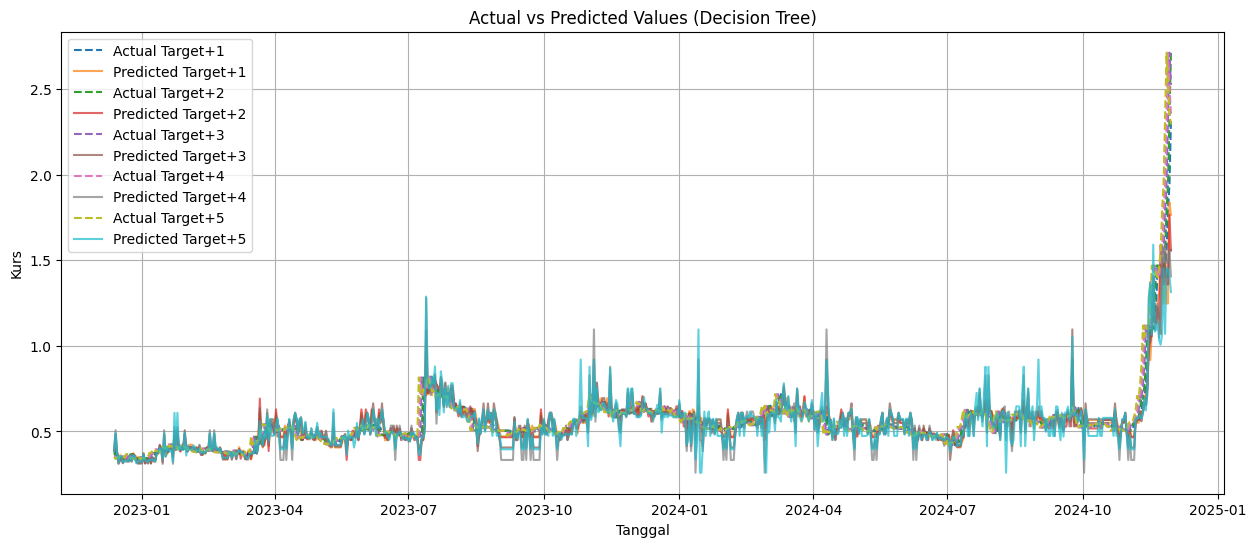
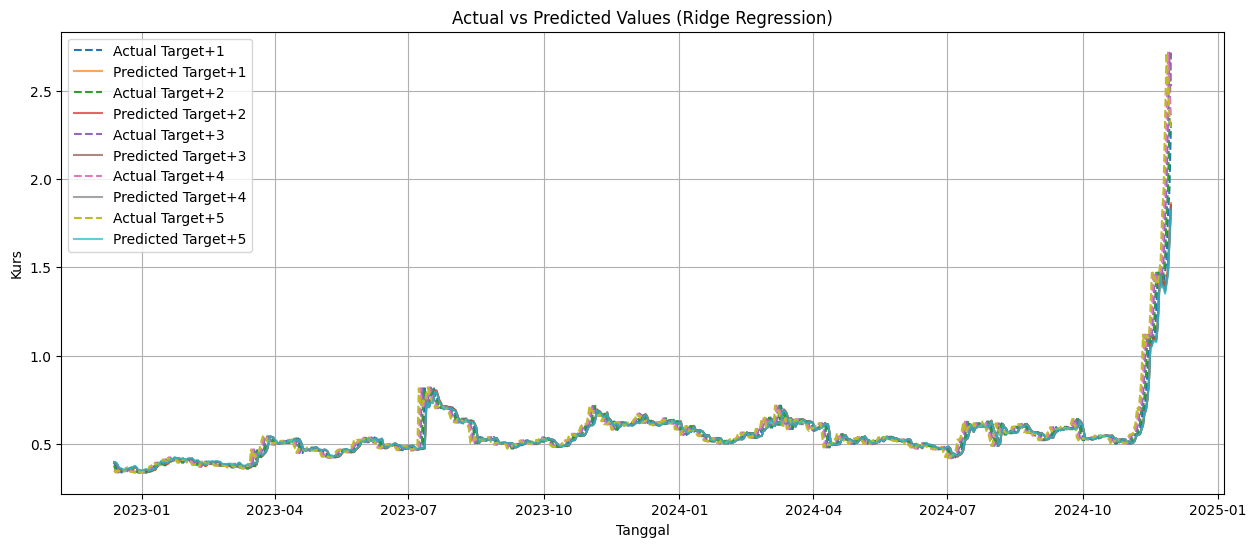
HASIL EVALUASI MODEL
Linear Regression:
Average RMSE: 0.03
Average MAPE: 5.44%
Decision Tree:
Average RMSE: 0.04
Average MAPE: 12.14%
Ridge Regression:
Average RMSE: 0.03
Average MAPE: 5.55%
Kesimpulan#
Berdasarkan hasil percobaan dengan beberapa model, metode Linear Regression menunjukkan performa terbaik dengan nilai RMSE sebesar 0.03 dan MAPE sebesar 5.44%.
DEPLOYMENT#
Hasil deployment dapat dilihat melalui tautan berikut: https://huggingface.co/spaces/Alifiacaca/projek3_prediksimonero