Laporan Proyek Sains Data 2#
Analisis Tren Historis untuk Prediksi Harga Gula#
PENDAHULUAN#
Latar Belakang#
Gulaku, didirikan pada tahun 2002, berkomitmen menyediakan gula berkualitas tinggi yang terjangkau bagi masyarakat Indonesia. Dengan visi keberlanjutan dan misi ramah lingkungan, Gulaku menjaga kualitas produk melalui teknologi modern dan kemasan steril. Selain itu, perusahaan mendukung inisiatif sosial dan ekonomi lokal di Lampung.
Sebagai produsen gula yang berfokus pada kualitas dan keberlanjutan, menghadapi tantangan signifikan dalam menjaga kestabilan harga dan ketersediaan produk di pasar yang sangat dinamis. Fluktuasi harga yang dipengaruhi oleh berbagai faktor eksternal seperti cuaca, kebijakan pemerintah, serta permintaan dan penawaran pasar dapat memengaruhi kestabilan produksi dan distribusi gula. Oleh karena itu, peramalan harga menjadi sangat penting bagi Gulaku untuk mengoptimalkan rantai pasokannya dan mengurangi risiko kerugian akibat ketidaksesuaian antara produksi dan permintaan pasar.
Dengan menggunakan analisis data historis, perusahaan dapat mengidentifikasi pola-pola harga yang mungkin terjadi di masa depan, sehingga memungkinkan perencanaan yang lebih matang dan efisien. Hal ini tidak hanya membantu dalam menjaga kestabilan harga dan ketersediaan produk, tetapi juga memperkuat posisi Gulaku di pasar yang kompetitif. Selain itu, peramalan yang akurat memungkinkan Gulaku untuk merespons perubahan pasar secara lebih cepat, mengurangi biaya operasional, dan meningkatkan kepuasan pelanggan. Oleh karena itu, penerapan model peramalan yang berbasis data historis ini merupakan langkah strategis untuk mendukung pengambilan keputusan yang lebih cerdas di tingkat produksi, distribusi, dan pengelolaan stok.
Tujuan#
Melalui analisis data historis, Gulaku dapat melakukan peramalan harga secara akurat untuk menjaga stabilitas harga di pasaran, memastikan ketersediaan produk yang konsisten, serta meminimalkan risiko kelebihan atau kekurangan stok. Dengan peramalan yang tepat, Gulaku dapat merencanakan produksi dan distribusi secara lebih efisien, serta mampu mempersiapkan diri terhadap perubahan cepat di pasar.
Rumusan Masalah#
- Bagaimana Gulaku dapat memprediksi harga di pasar gula yang dinamis sehingga produsen dan distributor dapat mengambil keputusan yang lebih baik terkait produksi, distribusi, dan persediaan?
METODOLOGI#
Data Understanding#
a. Sumber Data#
Data yang digunakan pada proyek ini diambil dari platform PHIPS Nasional (Pusat Informasi Harga Pangan Strategis Nasional), yang beralamat di https://www.bi.go.id/hargapangan. Platform ini menyediakan informasi harga strategi pangan yang meliputi berbagai komoditas, baik di pasar tradisional maupun modern, serta data berdasarkan daerah dan jenis pedagang. Informasi ini mencakup harga rata-rata, perubahan harga, dan juga fitur visualisasi seperti histogram dan tampilan peta. Selain itu, PIHPS menawarkan berbagai jenis informasi harga pangan antar daerah, yang sangat berguna untuk analisis pasar dan pengambilan keputusan terkait kebutuhan pangan. Dalam proyek ini, digunakan data harga pangan yang tersedia dalam format tabel dari situs PIHPS Nasional, khususnya data harga gula dari tanggal 1 Januari 2021 hingga 18 September. Bentuk tampilan datanya seperti berikut :
# import library
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LinearRegression
from sklearn.svm import SVR
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import BaggingRegressor
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_percentage_error
import seaborn as sns
import matplotlib.pyplot as plt
#Mengambil dan menampilkan data
df = pd.read_csv('https://raw.githubusercontent.com/chacalala/psd/refs/heads/main/Data%20Gula.csv')
pd.options.display.float_format = '{:.0f}'.format
print(df.head())
Date Harga
0 01/ 01/ 2021 15,750
1 04/ 01/ 2021 15,750
2 05/ 01/ 2021 15,750
3 06/ 01/ 2021 15,700
4 07/ 01/ 2021 15,700
b. Deskripsi Dataset#
Dataset ini terdiri dari 2 fitur atau kolom, dan 986 record. Berikut adalah deskripsi dari setiap atribut yang ada:
Date : Mengindentifikasi tanggal transaksi, biasanya memiliki format YYYY-MM-DD.
Harga Gula (kg): Menyimpan harga gula per kilogram, yang dapat berubah seiring waktu dan relevan dalam konteks pembelian.
Jenis Data:
Date : Data saat ini disajikan dalam bentuk string, namun akan diubah menjadi tipe data datetime pada tahap eksplorasi untuk memudahkan analisis waktu.
Harga Gula (kg): Numerik (Kontinu), karena harga dapat memiliki nilai pecahan dan dapat diukur dengan presisi yang lebih tinggi.
Selanjutnya, melihat tipe data dari setiap kolom
df.dtypes
Date object
Harga object
dtype: object
Kolom "Date" (object) berisi data dalam format teks, yang kemungkinan mewakili tanggal. Kolom "Harga" (object) bertipe teks, yang mungkin mengandung tanda koma atau simbol lainnya, sehingga perlu dikonversi ke tipe numerik (seperti float) untuk melakukan analisis.
c. Eksplorasi Data#
Sebelum melakukan eksplorasi data, kolom date akan dikonversi dari format string menjadi tipe data datetime dan dijadikan sebagai indeks dari DataFrame.
df['Date'] = pd.to_datetime(df['Date'], dayfirst=True, errors='coerce')
df.set_index('Date', inplace=True)
Selanjutnya, penting untuk memastikan bahwa kolom Harga Gula (kg) memiliki format yang benar agar bisa digunakan dalam perhitungan. Oleh karena itu, perlu mengubah kolom tersebut menjadi tipe data numerik dengan menghapus tanda koma yang mungkin ada.
df['Harga'] = df['Harga'].replace('-', np.nan).str.replace(',', '').astype(float)
print(df.head())
Harga
Date
2021-01-01 15750
2021-01-04 15750
2021-01-05 15750
2021-01-06 15700
2021-01-07 15700
Setelah itu, melihat apakah didalam data set tersebut ada missing value.
missing_values = df.isnull().sum()
print("Jumlah Missing Values di setiap kolom:")
print(missing_values)
Jumlah Missing Values di setiap kolom:
Harga 9
dtype: int64
Setelah dilakukan pengecekan, ternyata terdapat missing values pada kolom Harga sebanyak 9 nilai. Untuk menangani hal ini, kita akan menggunakan metode Forward Fill (ffill), di mana nilai terakhir yang valid akan dibawa ke depan untuk mengisi nilai yang hilang. Metode ini dipilih karena dianggap cocok untuk mempertahankan kontinuitas data berdasarkan tren historis.
df = df.ffill()
missing_values_after = df.isnull().sum()
print("\nJumlah Missing Values setelah penanganan:")
print(missing_values_after)
Jumlah Missing Values setelah penanganan:
Harga 0
dtype: int64
Selanjutnya melakukan pengecekan struktur dataset
df.info()
print('Ukuran data ', df.shape)
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 986 entries, 2021-01-01 to 2024-10-11
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Harga 986 non-null float64
dtypes: float64(1)
memory usage: 15.4 KB
Ukuran data (986, 1)
DataFrame diatas berisi 986 data dengan indeks waktu dari 1 Januari 2021 hingga 11 Oktober 2024. Terdapat satu kolom bernama "Harga" bertipe float64, dan semua datanya lengkap tanpa nilai kosong. Ukuran memori yang digunakan adalah 15,4 KB. Dataset ini siap digunakan untuk analisis, seperti memprediksi harga atau melihat tren waktu.
Selanjutnya, dilakukan eksplorasi data untuk mendapatkan statistik dasar dari kolom Harga.
df.describe()
| Harga | |
|---|---|
| count | 986 |
| mean | 16478 |
| std | 1334 |
| min | 13450 |
| 25% | 15550 |
| 50% | 15900 |
| 75% | 16850 |
| max | 19300 |
Terdapat 986 data yang dianalisis dengan rata-rata harga Rp16.477,84 dan penyebaran data (standar deviasi) sekitar Rp1.334,03, menunjukkan variabilitas harga. Harga terendah tercatat sebesar Rp13.450,00, sementara 25% data memiliki harga di bawah Rp15.550,00 (Kuartil 1), dan median atau harga tengah berada di Rp15.900,00. Sebanyak 75% data memiliki harga di bawah Rp16.850,00 (Kuartil 3), dengan harga tertinggi mencapai Rp19.300,00.
Data Preprocessing#
Sliding Window#
Melakukan penambahan fitur lag untuk harga gula yang merepresentasikan harga pada hari-hari sebelumnya. Kolom baru yang ditambahkan adalah Harga-1, Harga-2, dan Harga-3, yang masing-masing menunjukkan harga gula satu, dua, dan tiga hari sebelumnya. Nilai-nilai NaN yang muncul akibat pergeseran (lag) dihapus menggunakan fungsi `dropna`, sehingga hanya data yang lengkap yang tersisa. Kolom-kolom tersebut diatur ulang, sehingga kolom Harga (harga saat ini) berada di posisi terakhir, yang akan mempermudah analisis prediksi harga menggunakan model berbasis waktu.
df['Harga-1'] = df['Harga'].shift(1) # Harga satu hari sebelumnya
df['Harga-2'] = df['Harga'].shift(2) # Harga dua hari sebelumnya
df['Harga-3'] = df['Harga'].shift(3) # Harga tiga hari sebelumnya
df.dropna(inplace=True)
df = df[['Harga-3', 'Harga-2', 'Harga-1', 'Harga']]
print(df.head())
Harga-3 Harga-2 Harga-1 Harga
Date
2021-01-06 15750 15750 15750 15700
2021-01-07 15750 15750 15700 15700
2021-01-08 15750 15700 15700 15750
2021-01-11 15700 15700 15750 15700
2021-01-12 15700 15750 15700 15750
Normalisasi Data#
Melakukan normalisasi data pada fitur (Harga-1, Harga-2, Harga-3) dan target (Harga) menggunakan MinMaxScaler, pertama-tama normalisasi fitur dilakukan dengan scaler_features dan hasilnya disimpan dalam df_features_normalized. Kemudian, target harga dinormalisasi dengan scaler_target dan hasilnya disimpan dalam df_target_normalized. Setelah itu, kedua dataframe tersebut digabungkan dengan pd.concat untuk menghasilkan df_normalized, siap untuk analisis atau model prediksi selanjutnya..
# Inisialisasi scaler untuk fitur (input) dan target (output)
scaler_features = MinMaxScaler()
scaler_target = MinMaxScaler()
# Normalisasi fitur (Harga-1, Harga-2, Harga-3)
df_features_normalized = pd.DataFrame(scaler_features.fit_transform(df[['Harga-3', 'Harga-2', 'Harga-1']]),
columns=['Harga-3', 'Harga-2', 'Harga-1'],
index=df.index)
# Normalisasi target (Harga)
df_target_normalized = pd.DataFrame(scaler_target.fit_transform(df[['Harga']]),
columns=['Harga'],
index=df.index)
# Gabungkan kembali dataframe yang sudah dinormalisasi
df_normalized = pd.concat([df_features_normalized, df_target_normalized], axis=1)
df_normalized.head()
| Harga-3 | Harga-2 | Harga-1 | Harga | |
|---|---|---|---|---|
| Date | ||||
| 2021-01-06 | 0 | 0 | 0 | 0 |
| 2021-01-07 | 0 | 0 | 0 | 0 |
| 2021-01-08 | 0 | 0 | 0 | 0 |
| 2021-01-11 | 0 | 0 | 0 | 0 |
| 2021-01-12 | 0 | 0 | 0 | 0 |
Modelling#
a. Pembagian Data#
Selanjutnya, melakukan pembagian data menjadi data training dan data testing dengan menggunakan train_test_split, di mana 80% data digunakan untuk training dan 20% untuk testing. Proses ini dilakukan dengan opsi shuffle=False agar data tetap terurut berdasarkan urutan aslinya. Setelah pembagian, data training (X_train dan y_train) digunakan untuk melatih model, sedangkan data testing (X_test dan y_test) digunakan untuk menguji kinerja model yang telah dilatih.
# Mengatur fitur (X) dan target (y)
X = df_normalized[['Harga-1', 'Harga-2', 'Harga-3']]
y = df_normalized['Harga']
# Membagi data menjadi training dan testing (80% training, 20% testing)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
print('===== Data Train =====')
print(X_train)
print('===== Data Testing ====')
print(X_test)
===== Data Train =====
Harga-1 Harga-2 Harga-3
Date
2021-01-06 0 0 0
2021-01-07 0 0 0
2021-01-08 0 0 0
2021-01-11 0 0 0
2021-01-12 0 0 0
... ... ... ...
2024-01-04 1 1 1
2024-01-05 1 1 1
2024-01-08 1 1 1
2024-01-09 1 1 1
2024-01-10 1 1 1
[786 rows x 3 columns]
===== Data Testing ====
Harga-1 Harga-2 Harga-3
Date
2024-01-11 1 1 1
2024-01-12 1 1 1
2024-01-15 1 1 1
2024-01-16 1 1 1
2024-01-17 1 1 1
... ... ... ...
2024-10-07 1 1 1
2024-10-08 1 1 1
2024-10-09 1 1 1
2024-10-10 1 1 1
2024-10-11 1 1 1
[197 rows x 3 columns]
b. Penyusunan Model#
Pada tahap ini, dilakukan percobaan dengan menggunakan tiga model utama, yaitu Regresi Linear, Support Vector Regression (SVR), dan K-Nearest Neighbors (KNN). Selain itu, untuk meningkatkan akurasi dan kinerja model, diterapkan juga teknik ensemble dengan metode bagging
pip install matplotlib
Requirement already satisfied: matplotlib in c:\users\ryzen\appdata\local\programs\python\python311\lib\site-packages (3.9.3)
Requirement already satisfied: contourpy>=1.0.1 in c:\users\ryzen\appdata\local\programs\python\python311\lib\site-packages (from matplotlib) (1.3.1)
Requirement already satisfied: cycler>=0.10 in c:\users\ryzen\appdata\local\programs\python\python311\lib\site-packages (from matplotlib) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in c:\users\ryzen\appdata\local\programs\python\python311\lib\site-packages (from matplotlib) (4.55.2)
Requirement already satisfied: kiwisolver>=1.3.1 in c:\users\ryzen\appdata\local\programs\python\python311\lib\site-packages (from matplotlib) (1.4.7)
Requirement already satisfied: numpy>=1.23 in c:\users\ryzen\appdata\local\programs\python\python311\lib\site-packages (from matplotlib) (2.1.2)
Requirement already satisfied: packaging>=20.0 in c:\users\ryzen\appdata\local\programs\python\python311\lib\site-packages (from matplotlib) (24.2)
Requirement already satisfied: pillow>=8 in c:\users\ryzen\appdata\local\programs\python\python311\lib\site-packages (from matplotlib) (11.0.0)
Requirement already satisfied: pyparsing>=2.3.1 in c:\users\ryzen\appdata\local\programs\python\python311\lib\site-packages (from matplotlib) (3.2.0)
Requirement already satisfied: python-dateutil>=2.7 in c:\users\ryzen\appdata\local\programs\python\python311\lib\site-packages (from matplotlib) (2.9.0.post0)
Requirement already satisfied: six>=1.5 in c:\users\ryzen\appdata\local\programs\python\python311\lib\site-packages (from python-dateutil>=2.7->matplotlib) (1.16.0)
Note: you may need to restart the kernel to use updated packages.
# List model untuk ensemble Bagging
models = {
"Linear Regression": LinearRegression(),
"SVR": SVR(),
"KNN": KNeighborsRegressor(n_neighbors=5)
}
# Dictionary untuk menyimpan hasil evaluasi
results = {}
# Iterasi setiap model
for i, (name, base_model) in enumerate(models.items()):
# Inisialisasi Bagging Regressor dengan model dasar
bagging_model = BaggingRegressor(
estimator=base_model,
n_estimators=30,
max_samples=0.8, # Menggunakan 80% dari data latih
max_features=1.0, # Menggunakan semua fitur
bootstrap=True, # Menggunakan bootstrap sampling
random_state=42
)
# Latih model
bagging_model.fit(X_train, y_train)
# Prediksi pada data uji
y_pred = bagging_model.predict(X_test)
# Evaluasi model
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
mape = mean_absolute_percentage_error(y_test, y_pred) * 100 # Dalam persen
# Simpan hasil evaluasi
results[name] = {"RMSE": rmse, "MAPE": mape}
# Kembalikan hasil prediksi ke skala asli
y_pred_original = scaler_target.inverse_transform(y_pred.reshape(-1, 1))
y_test_original = scaler_target.inverse_transform(y_test.values.reshape(-1, 1))
# Plot hasil prediksi
plt.figure(figsize=(15, 6))
plt.plot(y_test.index, y_test_original, label="Actual", color="blue")
plt.plot(y_test.index, y_pred_original, label=f"Predicted ({name})", color="red")
# Tambahkan detail plot
plt.title(f'Actual vs Predicted Values ({name})')
plt.xlabel('Tanggal')
plt.ylabel('Harga')
plt.legend()
plt.grid(True)
# Tampilkan plot
plt.show()
# Tampilkan hasil evaluasi
print("HASIL EVALUASI MODEL")
for model, metrics in results.items():
print(f"{model}:\n RMSE: {metrics['RMSE']:.2f}\n MAPE: {metrics['MAPE']:.2f}%\n")
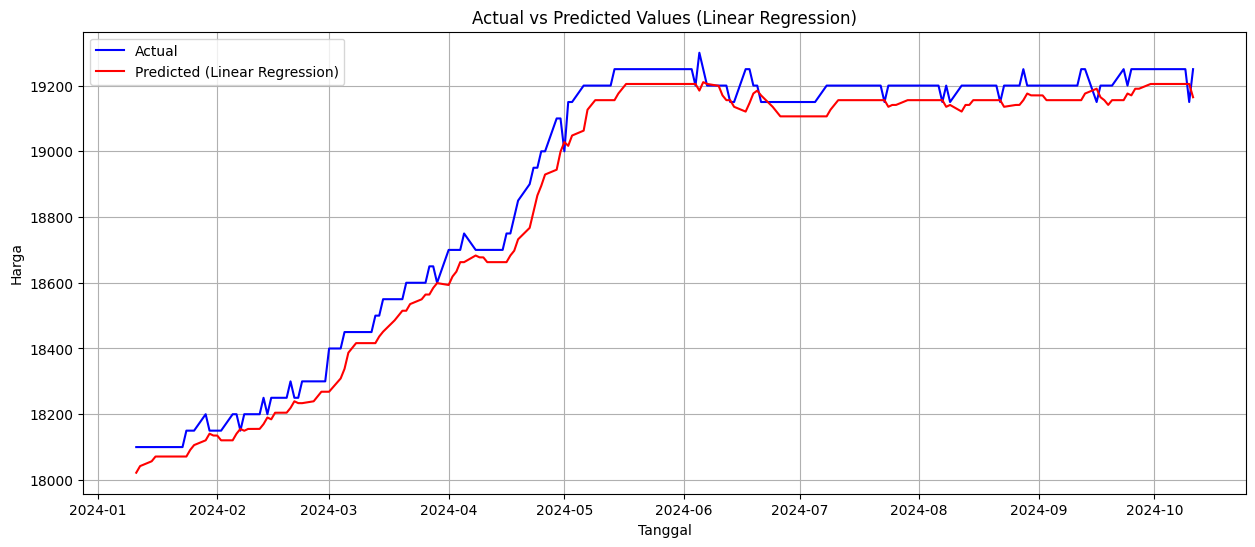
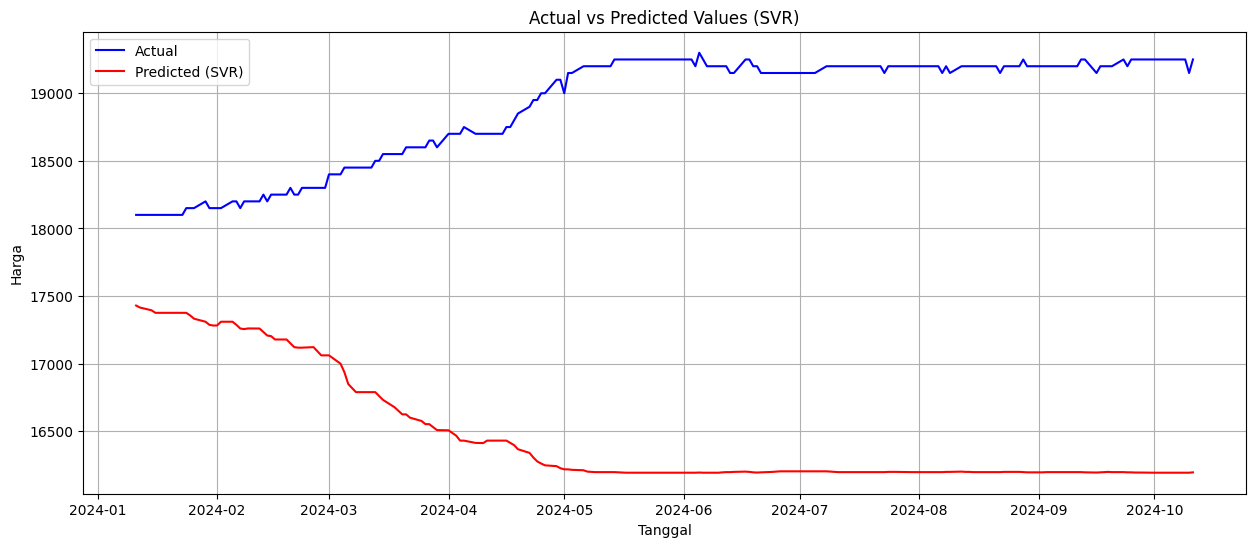
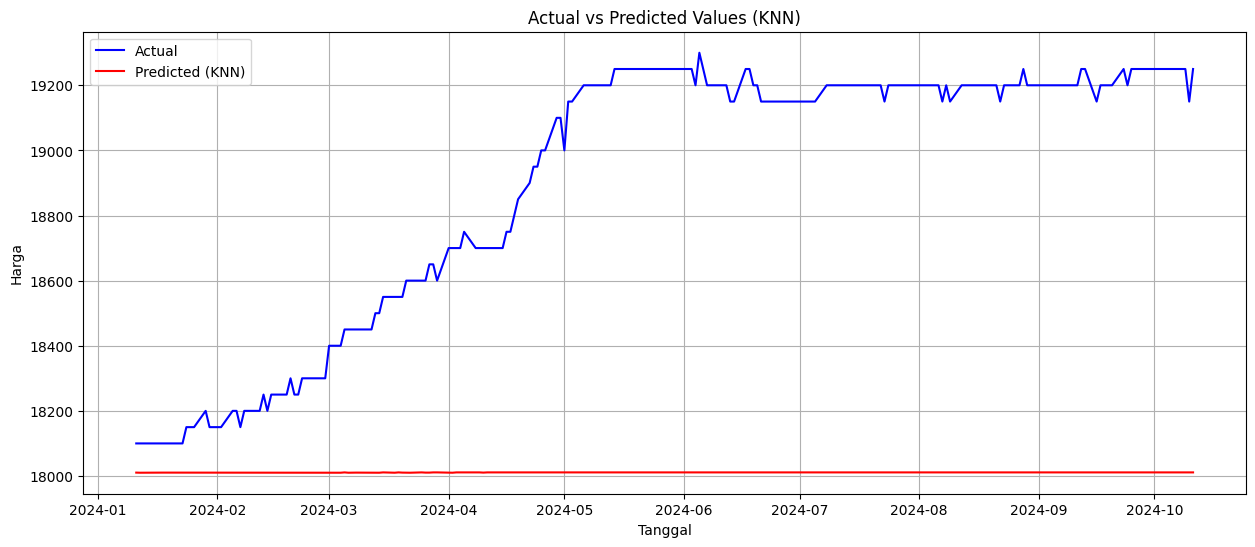
HASIL EVALUASI MODEL
Linear Regression:
RMSE: 0.01
MAPE: 0.98%
SVR:
RMSE: 0.44
MAPE: 43.70%
KNN:
RMSE: 0.17
MAPE: 15.85%
Kesimpulan#
Berdasarkan hasil percobaan dengan beberapa model, metode Linear Regression menunjukkan performa terbaik dengan nilai RMSE sebesar 0.01 dan MAPE sebesar 0.98%.
DEPLOYMENT#
Hasil deployment dapat dilihat melalui tautan berikut: https://huggingface.co/spaces/Alifiacaca/projek2_prediksigula